Vandaag ben ik te gast bij het KW1C voor de 39ste saMBO-ICT Conferentie. JaapJan Vroom van Deltion vertelt over hun initiatieven op het gebied van Learning Analytics. Ze begonnen met een verkenning naar wat ze konden meten om pas erna te kijken wat ze wilden. De vraag “Waar moet Learning Analytics een antwoord op geven?” was volgend. JaapJan was de eerste om toe te geven dat je normaal gesproken daar mee moet starten maar begrijpelijk dat je tijdens een verkenning andersom aanpakt.
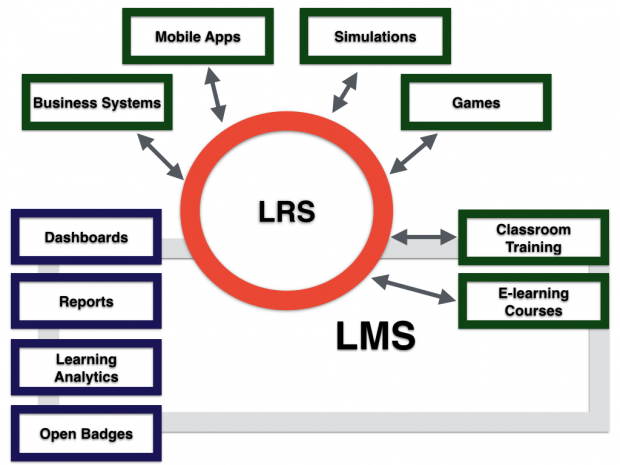
Ze werken met Xerte als auteurstool voor online lesmateriaal. Ze investeerden om Xerte te voorzien van xAPI en aan te sluiten op een LRS (Learning Record Store). In de pre-pilot gebruikten ze deze voor professionaliseringsmodule voor docenten (slim want geen studentengegevens en AVG ‘gedoe’).
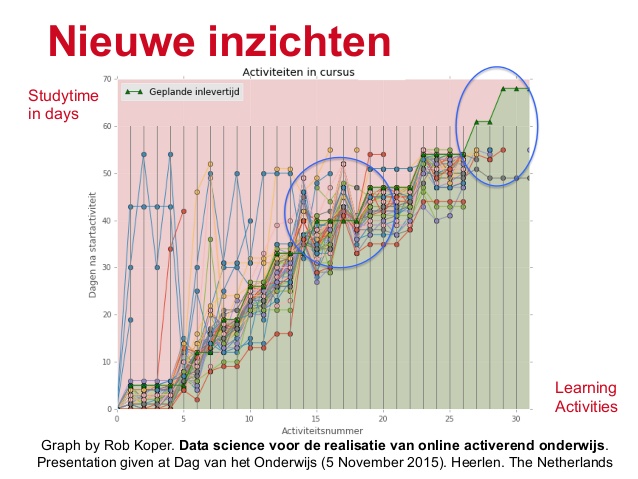
Wat ik frappant vindt, is dat tijdens het leren een soort ‘activiteiten-stroom’ ontstaat die in gewone taal te begrijpen is. Bijvoorbeeld: pagina X is gestart, beëindigt, opdracht Y is gescored, video Z is bekeken etc. Per ‘statement’ is dit niet zo relevant, maar over het totaal zijn interessante rapportages te maken.
Het roep veel vragen op maar voor dit stadium (verkenning in een pre-pilot) is dat logisch, tegelijk kom je dan op ideeën. Bijvoorbeeld: een uitgever geeft nu alleen een eindresultaat terug aan de school, maar met deze techniek zou ook het leerproces daar naar toe, inzichtelijk gemaakt kunnen worden. In de volgende stap willen ze wel degelijk naar studenten-gegevens kijken natuurlijk. JaapJan heeft daarom ideeën over gebruiksvriendelijke manieren om ‘consent’ vast te leggen.
Overigens zie ik dat wel vaker bij innovatieve trajecten: eerst praktisch ervaring opdoen over wat er kan en aan beeldvorming doen en dan pas kijken hoe en of dit nuttig is. En niet andersom door vaak lang bezig te zijn met mooie doelen en de ‘waarom’ vraag, terwijl je eigenlijk niet op gang komt. Leren door doen dus.