Als Statline fan wilde ik graag aansluiten bij de bijeenkomst vandaag bij de MBO Raad over de pilot “Ontwikkeling CBS tabellen arbeidsmarktpositie mbo-schoolverlaters”. Deze ontwikkeling vind ik erg positief omdat we voor het doorlichten van ons opleidingsassortiment onder andere een indicator voor ‘Arbeidsmarktrelevantie‘ gebruiken. De data hiervoor kwam tot nu toe van “Kans op Werk” (waarvoor dank), maar zo’n indicator behoeft wel doorontwikkeling. Overigens is onderwijsaanbod en arbeidsmarkt niet mijn terrein van expertise. Data aan elkaar knopen (of mooier gezegd: integrale informatie creëren op basis van meerdere databronnen) natuurlijk wel.
Even wat achtergrond:
“Het Centraal Bureau voor de Statistiek (CBS) heeft als pilot, op verzoek van het ministerie van Onderwijs, Cultuur en Wetenschap (wat betreft het groen mbo mede namens het ministerie van Economische Zaken), per onderwijsinstelling in het middelbaar beroepsonderwijs (mbo) tabellen samengesteld over de resultaten van schoolverlaters op de arbeidsmarkt.
Het doel van deze tabellen is om mbo-instellingen te ondersteunen bij het afstemmen van het onderwijsaanbod op de regionale arbeidsmarkt, n.a.v. zorgplicht en het actieplan MBO ‘Focus op vakmanschap 2011-2015.”
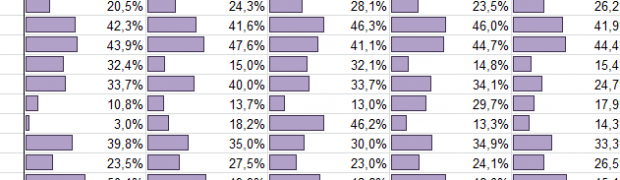
Vandaag werden de eerste tabellen getoond. Deze tonen per BRIN en crebo/kwalificatiedossier het aantal schoolverlaters dat (g)een diploma heeft, (g)een baan of uitkering en de bedrijfstak waar de MBO-er in terecht is gekomen. Overigens zal de precieze inhoud moeten blijken uit een specificatie. Samen met definities en berekeningen zou deze documentatie dan als bijsluiter kunnen dienen. Dit kan helpen voorkomen dat conclusies te snel of te krom worden getrokken. Plaats hiervoor zou de informatie-encyclopedie zijn.
De eerste indruk is positief. Eerst waren deze cijfers er niet, nu wel. Toch blijkt het moeilijk te zijn om een integraal beeld van deelnemers, hun opleiding, latere beroep, werkgever en branche te maken. Liefst per regio. Hier spelen een paar zaken een rol:
-
Het koppelen van data is moeilijk, niet zozeer technisch als wel qua gegevens. De koppelbaarheid van 2 bronnen vereist minstens één gegeven dat zich in beide bronnen bevindt en deze moet dan nog zinvol zijn. Voorbeelden:
- Het CBS heeft de cijfers van de bedrijfstak waar iemand werkt. DUO heeft de gegevens van de opleiding van datzelfde individu. Zo kun je op BRIN en Crebo de uitstroom naar bedrijfstak bepalen. De gebruikte classificatie is het ‘SBI’ oftwel de Standaard Bedrijfsindeling. Das handig, als de opleiding slager leidt tot het beroep slager in een slagersbedrijf. Maar een secretaresse met secretaresse-opleiding die bij een bouwbedrijf werkt, een beveiliger in een ziekenhuis, een student van de opleiding receptionist van een hotelschool die baliemedewerker wordt bij een financiële instelling omdat ze zo klantvriendelijk zijn, tja ….
- Het ROA gebruikt een beroepenclassificatie in plaats van een bedrijfsindeling. Opzich handiger, maar de gegevens per individu worden middels enquete uitgevraagd. De koppelbaarheid met Crebo verdwijnt dan, er is niets meer te rapporteren per school en het leidt tot handmatige analyses, geen geautomatiseerde rapportages.
- Belangen van aanspraakmakers, meetbaarheid en privacy: Er moet langs de ‘klippen van de privacy-wet’ gevaren worden. Let wel: om je er aan te houden dus. De enige manier om geautomatiseerd een integraal beeld te krijgen van opleidingen, is door per individu zowel de schoolloopbaan als zijn beroepsloopbaan te registreren. Ten eerste is er geen instituut dat alle benodigde velden registreert, ten tweede is het koppelen daarvan per individu alleen mogelijk als instituten deze gegevens uitwisselen. Bijvoorbeeld, als DUO de schoolloopbaan levert, de Belastingdienst het inkomen en werkgever vertelt, ROA/CBS of iemand anders het beroep geeft en de gemeente de woonplaats levert dan kun je weten welke opleiding:
-
- voor welke bedrijfstak opleidt.
- voor werkeloosheid opleidt.
- voor welk beroep opleidt.
- voor welke (europese) functie- of inkomens-schalen opleidt.
- een regionaal karakter heeft.
Samengevat: ik ben wel blij met de ontwikkeling van deze tabellen. Het helpt adviseurs binnen MBO’s om een beeld te krijgen van de relevantie van hun opleidingen. Echter: voorlopig blijft het zo dat je handmatig verschillende invalshoeken langs elkaar moet leggen om zelf een beeld te krijgen. Dit is een tijdrovende klus, waarvan de automatisering nog op zich laat wachten lijkt me.